Ami megerősít, az meg is ölhet

B. F. Skinner, a Harvard pszichológus professzora rendkívüli módon unta a jutalomfalat-gyártást, melyre viszont igen nagy szükség volt, hiszen laboratóriumában kiéheztetett galambok és rágcsálók sora várta a pedálok és gombok nyomogatásáért járó pozitív megerősítést. Az ehhez szükséges pasztillák előállítása egy Skinner által sajátkezűleg, egy környékbeli gyógyszerész berendezésének mintájára készített géppel történt. A folyamatról a következőket írja:
“Lassú és gyötrelmes procedúra volt. A nyolc patkány a fejenként napi százdarabos pasztillafogyasztásával könnyedén felélte a legyártott adagot. Egy szép szombat délután nekiláttam, hogy felmérjem a pasztilla-készleteket, s az elemi aritmetika néhány alapvető tételének segítségével arra a következtetésre jutottam, hogy ha csak nem töltöm a délután hátralévő részét tablettagyártással, a készletek legkésőbb hétfő reggel fél tizenegyig ki fognak merülni. […] Ez vezetett ahhoz, hogy […] megkérdezzem magamtól: miért is kellene minden egyes gombnyomást jutalommal megerősítenem? Úgy döntöttem, hogy csak percenként egy válaszreakciót fogok jutalmazni, s a többit megerősítés nélkül hagyom. Ez két eredményhez vezetett: a) a pasztillakészletek szinte a végtelenségig kitartottak b) mindegyik patkány stabil válaszadási hajlandóságot mutatott." 1
Így kezdődött el az a munka, melyre sok modernkori – többek között motivációval, függőséggel, játékszenvedéllyel és mentális betegségekkel foglalkozó – kutatás is épül. Skinner a fenti idézetben periodikus megerősítés-ként írja le, a kortárs szakirodalomban VI/VR reinforcement schedule (változó intervallumos és változó arányú megerősítési rendszer) néven hivatkoznak rá, de sokan intermittent reinforcement 2 néven ismerik.
A középagyi dopaminsejtek aktivitása fontos szerepet játszik a jutalommal kapcsolatos arousal (izgatottság érzés) és az ebből fakadó, a jutalom megszerzésére irányuló viselkedés kialakulásának és fenntartásának folyamatában. A dopaminkísérleteknek köszönhetően kiderült, hogy az izgalmi állapot a jutalom tényleges megszerzését megelőzően, az anticipációs (jutalomra való várakozás) szakaszban közel azonos vagy magasabb, mint a jutalom megszerzésének pillanatában, majd azt követően – amennyiben egy kiszámítható megerősítési rendszerről van szó – gyors hanyatlásnak indul. Amennyiben kiszámíthatatlan megerősítési rendszerben történik mindez, a válaszreakció tartósabb, nem esik vissza azonnal. 3
Megvizsgálták azt is,4 hogy milyen szintű izgalmat vált ki a kilátásba helyezett pozitív megerősítés annak függvényében, hogy az mekkora valószínűséggel fog bekövetkezni. A kísérletben részt vevő majmokat arra kondicionálták, hogy képesek legyenek megkülönböztetni öt markánsan eltérő probabilitási szintet, ezt követően vizsgálták a jutalmat előre jelző ingerre adott reakciójukat. Az alábbi sematikus ábrán szemléltetném az eredményt (kizárólag tájékoztató jellegű ábra, pontos mérési adatokért a tanulmányt javaslom megtekinteni):
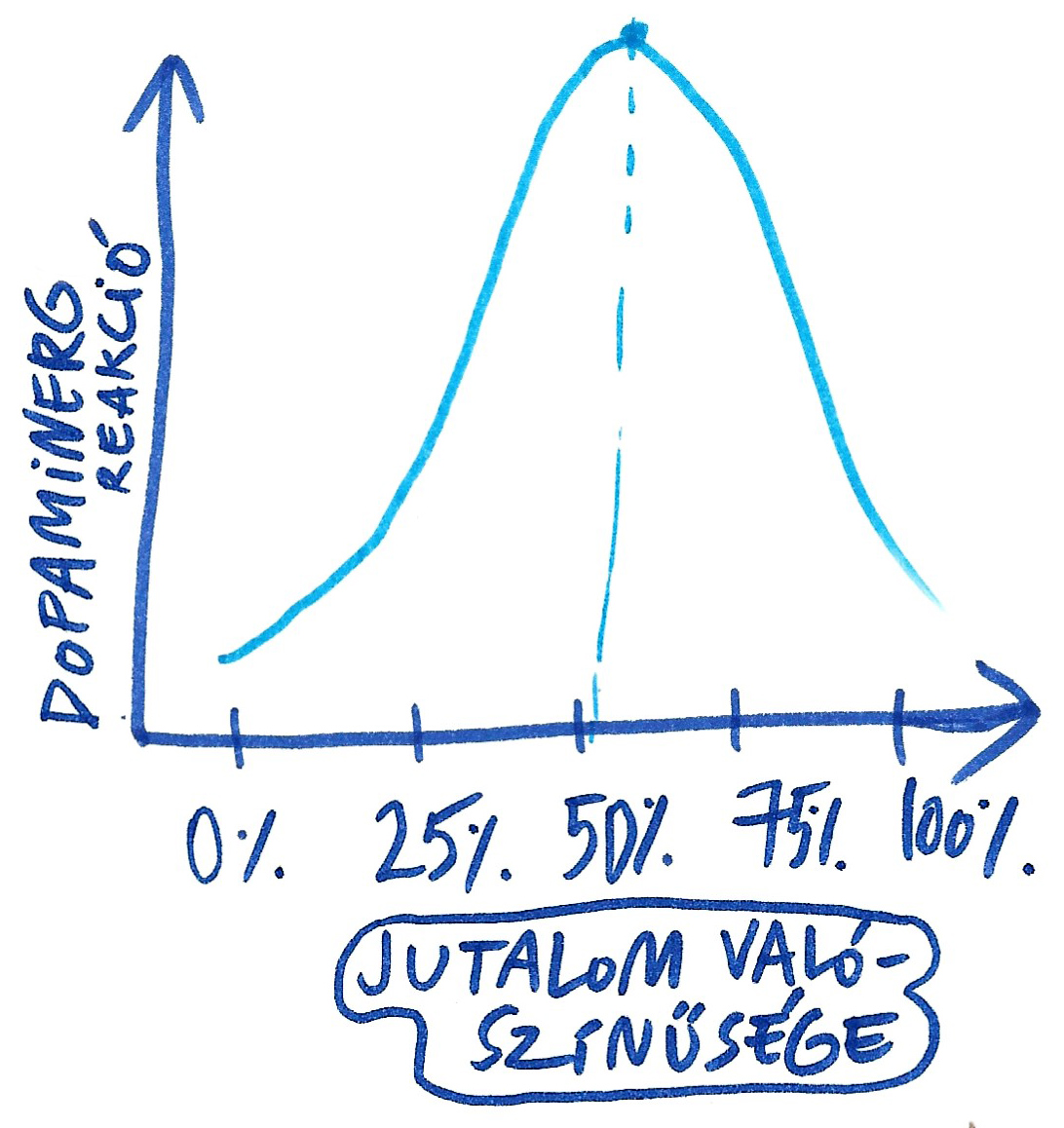
A dopaminsejtek folyamatos aktivitási szintjét (sustained activity) mérve a kutatók arra jutottak, hogy ez az 50%-os valószínűségi szintnél (mely értelemszerűen a legbizonytalanabb kimenetelű régió) a legmagasabb és legstabilabb. Olyannyira, hogy csaknem teljesen független attól, hogy a pozitív megerősítés bekövetkezik-e, vagy elmarad.
A kísérleti majmok lankadatlan, feszült eufóriában várják, hogy mikor lesz szerencséjük. Ez a valószínűségi szint az igazi sweet spot: a „vagy igen, vagy nem” kecsegtető állapota, a levegőben perdülő pénzérme, a félig lekapart sorsjegy, a pörgő rulettkerék várakozással teli pillanatai. A 25% és 75% körüli értékekhez társuló helyzetek már túl sok vagy túl kevés bizonyosságot rejtenek ahhoz, hogy ekkora izgalmat váltsanak ki, így a neurális reakció is valamivel lagymatagabb. A haranggörbe két lábánál – a 0% és 100% esetében – az abszolút IGEN és abszolút NEM földjén már síri csönd és teljes érdektelenség honol. Ami garantált, az épp annyira értéktelen, mint ami teljesen kizárható.
A jutalom elvárt és tényleges mértéke közötti pozitív eltérés (reward prediction error)5 különlegesen magas aktivitást indukál, azaz a vártnál nagyobb mennyiségben és minőségben, ill. nem várt időpontban érkező jutalomra adott dopaminsejt-reakció mindennél erősebb.
Lehetséges magyarázat és kiutak
Nüansznyi a különbség a mérgező párkapcsolatokban vergődők, az agymosott irodai rabszolgák és a megfelelően kondicionált laboratóriumi patkányok között. A jutalom reményében felszabaduló dopamin hasonlóan modulálja mindhármójuk viselkedését, függetlenül a konkrét élethelyzettől és állatrendszertani besorolástól. A kétes eséllyel érkező bónuszban, fizetésemelésben vagy előléptetésben bízó alkalmazott szintén nála hatalmasabb neurokémiai folyamatok által hajtva csapkodja kicsiny rágcsáló mancsaival az elé tett billentyűzetet.

Minden alkalommal, mikor a szeretőd minden előjel nélkül elutasít téged, csak hogy kicsit később ugyanennyire meglepő módon nyájasan közeledjen feléd; ha váratlanul kirobbanó aggresszióval büntet vagy bizonytalanságban tart, szakít veled, majd újra visszakönyörgi magát a kegyeidbe: (feltehetően) ösztönösen az intermittent reinforcement stratégiáját játssza ki ellened. Ennek a manipulációs módszernek a lényege, hogy pszichológiai függést alakítson ki benned az általa önkényesen és szeszélyes időközönként adagolt “jutalom” iránt. Természetesen ez nem működhet egy pre-kondicionáló szakasz nélkül, melyet konyhanyelven “love-bombing”-nak (szeretettel bombázás) neveznek. Ennek során az áldozat rendszeresen és a vártnál nagyobb adagokban kapja a dopaminergikus izgalmakat kiváltó pozitív megerősítést, ami tehát lényegében nem más, mint egy FR/FI (fix arányú vagy intervallumú) megerősítési program. Ez a tanulási szakasz (melynek során kódolódik a jutalom szubjektív értéke) a későbbiekben nem ismétlődik meg, innentől a már említett (a)periodikus szakasz kezdődik, ahol a megerősítés hol elmarad, hol nem. Te pedig szakadatlanul csipkeded csőröddel az eléd tett jelzőgombot, vagy kétségbeesetten nyomkodod a pedált – attól függően, hogy éppen milyen állat vagy.
Miért van, hogy a megjósolhatatlan kimenetelű szituációk váltják ki a legintenzívebb dopaminergikus reakciókat? Miért vonzó, ami kiszámíthatatlan? Miért maradunk benne azokban a helyzetekben, melyek ámítanak és gyötörnek?
A fent említett tanulmány megkísérel magyarázatot adni arra, hogy vajon mi okozhatja ezt a látszólagos anomáliát. Feltételezésük szerint a bizonytalanság figyelemfelhívó jelzésértékkel bír az organizmus számára. Ha nem vagyunk benne biztosak, hogy mi fog történni, az – természetes tanulási környezetekben – egy adaptív tapasztalatszerzési lehetőség: elképzelhető, hogy az egyed bizonytalansága a rendelkezésre álló prediktorok és információk hiányából fakad, így a magas dopaminaktivációs szint kellő lendületbe hozza az agy tanulási mechanizmusait ahhoz, hogy megértse, mi hiányzik a teljes képhez. Mivel feltételezhető, hogy van mit tanulni a helyzetből s ily módon a jövőbeli bizonytalanság mérsékelhető, az organizmus több energiát szentel a bizonytalan körülmények között történő empirikus tanulásra.
Mi van akkor azonban, ha nincs semmiféle levonható tanulság? Amikor a vagyigen-vagynem mechanizmust önkényesen használják ellenünk, egy mesterséges szituációt kreálva, melyben a szabályok folyton változnak? Sőt, talán az esélyeinkről elhitetett információk is hamisak, lehet, hogy nem is nyerhetünk?
Az eddigiek alapján tehát megállapíthatjuk, hogy a kelepce felállításához és fenntartásához alapvetően két faktor jelenléte szükséges:
1.) a jutalomszerzés (vélt vagy tényleges) 50%-os probabilitási rátája,
2.) a jutalom (vélt vagy ténylegesen) magas értéke.
Bármi legyen is az a pozitív kimenettel áltató körülmény, mely gúzsba köt, legalább részben egészen biztosan ezen a két pilléren nyugszik mérgező vonzereje. Ebből következik, hogy a helyzet hatástalanításához a bizonytalanság kiiktatásával, és/vagy a jutalom devalválásával kerülhetünk közelebb. Ez utóbbi valószínűleg nehezebben kivitelezhető, hiszen az, hogy mi tesz egy jutalmat értékessé, rendkívül komplex és nagyrészt szubjektív eredetű kérdés. Közrejátszik a meghatározásában, hogy deprivációs szakaszban érkezik-e (ha éhesek vagyunk, a száraz kiflivég is felértékelődik), váratlan mennyiségben/minőségben kapjuk-e, mennyire hamar kapjuk meg és így tovább. A bizonytalanság kiiktatása talán valamivel könnyebben elérhető, hiszen ha felismerjük és elfogadjuk, hogy az 50%-os sikerrel aktív részvételre csábító szcenárióban a siker tényleges valószínűsége az alacsonyabb probabilitási szintek irányába konvergál, a bizonytalansági faktor – némi csalódás és szívfájdalom árán ugyan, de – kiküszöbölhető.
Felhasznált irodalom:
Robinson MJF, Anselme P. How uncertainty sensitizes dopamine neurons and invigorates amphetamine-related behaviors. Neuropsychopharmacology. 2019 Jan;44(2):237-238. doi: 10.1038/s41386-018-0130-9. Epub 2018 Jun 29. PMID: 29959440; PMCID: PMC6300523.
Linnet, Jakob: Neurobiological underpinnings of reward anticipation and outcome evaluation in gambling disorder / https://www.frontiersin.org/articles/10.3389/fnbeh.2014.00100
-
Skinner, B. F. (1956). A case history in scientific method. American Psychologist, 11(5), 221–233. https://doi.org/10.1037/h0047662 ↩︎
-
A továbbiakban az egyszerűség kedvéért az intermittent reinforcement kifejezést fogom használni annak ellenére, hogy sem a terminus pontos eredetét nem sikerült tisztáznom, sem megbízható forrásból származó egzakt definíciót nem találtam hozzá (leszámítva talán ezt: https://dictionary.apa.org/variable-ratio-schedule). Mégis ezt tartom a leghatékonyabb megoldásnak, hiszen ez talán a laikusok körében legelterjedtebb ide köthető kifejezés. ↩︎
-
„Ratio schedules engender high rates of responding, more or less uniform under VR, consisting of a post-reinforcement pause or break followed by a run of high rate responding under FR.” – Killeen PR, Posadas-Sanchez D, Johansen EB, Thrailkill EA. Progressive ratio schedules of reinforcement. J Exp Psychol Anim Behav Process. 2009 Jan;35(1):35-50. doi: 10.1037/a0012497. Erratum in: J Exp Psychol Anim Behav Process. 2009 Apr;35(2):152. PMID: 19159161; PMCID: PMC2806234. ↩︎
-
Fiorillo CD, Tobler PN, Schultz W. Discrete coding of reward probability and uncertainty by dopamine neurons. Science. 2003 Mar 21;299(5614):1898-902. doi: 10.1126/science.1077349. PMID: 12649484. ↩︎
-
Schultz W. Dopamine reward prediction error coding. Dialogues Clin Neurosci. 2016 Mar;18(1):23-32. doi: 10.31887/DCNS.2016.18.1/wschultz. PMID: 27069377; PMCID: PMC4826767. ↩︎